Data Collection
Tweepy Data Collection
We collected data on known verified users from Twitter using the free, standard Tweepy API documented here: http://www.tweepy.org.
The verified users were identified manually and somewhat ‘at random’ by looking at Twitter’s desktop application. We did not discover a more automated, scalable way of doing this. In the end, we identified approximately 200 such accounts. For each account, we used Tweepy’s ‘tp.curor’ and ‘api.user_timeline’ methods to collect about 150 tweets per user.
We originally also collected tweets for users of unknown status (i.e., un-verified) but removed from analysis, focusing on binomial classification only (i.e., known-bot vs. known-verified users).
Known Bot Collection
A massive collection of over 200k tweets from known russian trolls were collected from the following location over at NBC News: https://www.nbcnews.com/tech/social-media/now-available-more-200-000-deleted-russian-troll-tweets-n844731
Data Fields
Diagram: Simple Data Model
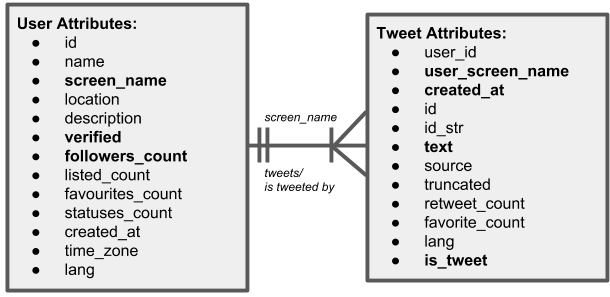
The above diagram shows the data fields we collected for the user and tweet objects from the two sources listed above. As the diagram depicts, we stored our data intially in 2 separate entities with the ability to join the data using screen_name.
The fields in bold are the fields we relied upon in our work. As noted in our conclusions and future considerations, more could be done with the fields that we did not make use of. Here is a description of the bolded fields that we did use in our analysis (and how we used them):
- User Related
- screen_name: This is user handle on Twitter (e.g., realDonaldTrump).
- verified: This is boolean flag representing if the account is verified manually by Twitter. We used for classification.
- followers_count: This is number of other users following the account. We used as feature in modeling.
- Tweet Related
- user_screen_name: This is screen name of person sending the tweet (or resending the retweet). We used to join with user data.
- created_at: This is date timestamp for when tweet or retweet was sent by user.
- text: This is text of tweet or text of orignal tweet being re-tweeted.
- is_tweet: This is a boolean flag indicating the tweet is a tweet and not a retweet. We created using regular expressions to find or not find ‘RE’ at the beginning of the text, which we were forced to rely on as re-tweet flag as the Twitter provided re-tweet flag was not available through the free, standard Tweepy API.
Cleaning
In our preliminary review of our data, we encountered the following issues which we resolved as described:
-
Tweepy’s API provides “tweets” that are both tweets and retweets. Accordingly, Tweepy’s documentation indicates Twitter provides a retweet flag for tweet objects that are actually retweets. We noticed tweepy was not providing this retweet flag in our test data. We investigated and concluded this was due to our using the standard, free API (in contrast to a paid for service level). We “corrected” for this missing data by setting the retweet flag ourselves when the tweet text includes “RT”, which seems to be inserted into the text field by Twitter for all retweets.
-
As described above, we are getting data from two sources: Twitter directly and the NBC news website. Our intention was to use the userid in the tweet data as our foreign key to data in the user table. When we analyzed data provided for bots by NBC, we noticed the userid field was largely empty. We explored the NBC data and inferred they used an alternative field (‘screen name’) to link its tweets to its user table. We went back and adopted this same strategy for linking tweets to users for data from Twitter as well.
-
Based on research into similar projects, we expect the timing of tweets throughout the day to play a role in classification. Our attempts to explore this relationship were originally limited by our discovering that moving data in and out of .json files with certain techniques resulted in the datetime stamp becoming corrupt for a majority of our tweets. We tried many alternative methods of reading/writing .json files until we were able to retain the accuracy of the datetime stamp (writing to .json via df.to_json(orient=’records’) and reading via pd.read_json()).
The final, resulting data frame was used across both analysis: the Microsoft Azure and NLTK groups.